前言
这是A Week系列的第四期。
主要是开了一个新坑,讲讲McKenney大师写的Parallel Programming,因为本书在国内尚无正式的译本,所以多写了一些翻译和理解。
Chapter 1
Is Parallel Programming Hard, And, If So,What Can You Do About It?
作者Paul E. McKenney是世界并行编程专家,Linux 内核中 RCU 实现和 rcutorture 测试模块的维护者,也是RCU的发明人。

在一开始有关于使用本书的指南,主要是一些代码和习题的初衷。

下面进入正式的章节:
Chapter 2 Introduction

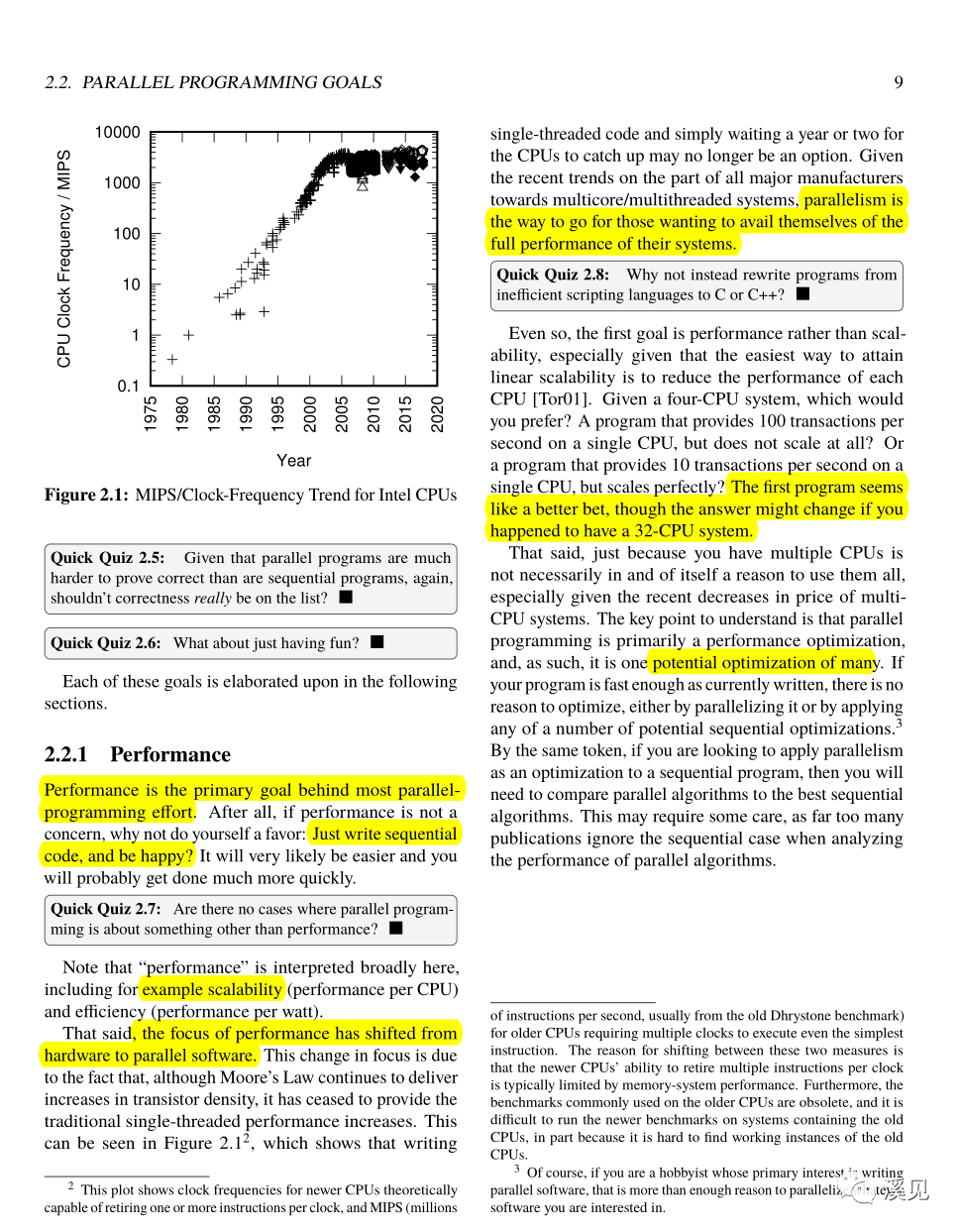
New technologies that are difficult to use at introduction invariably become easier over time.新事物总是在开始很难,但随着长时间的普及而变得简单。
It instead examines the reasons why parallel programming is difficult, and then works to help the reader to overcome these difficulties.
因为并行编程确实很难,但是这些困难都会克服的。
包括以下几个方面:
-
The historic high cost and relative rarity of parallel systems.
-
The typical researcher’s and practitioner’s lack of experience with parallel systems.
-
The paucity of publicly accessible parallel code.
-
The lack of a widely understood engineering discipline of parallel programming.
-
The high overhead of communication relative to that of processing, even in tightly coupled shared-memory computers.
除了因为是未知性较高,部分也是因为关联性复杂、运算代价高、通信繁琐。

虽然现存的大部分是并发编程,但随着计算机体系结构的发展,以及操作系统内核、数据库系统和消息处理系统的提升,并行编程的潜力将得到释放,虽然相对的通信成本还过高,但颇有点"苦尽甘来"的感觉。
并行编程的三个目标:
-
Performance.性能
-
Productivity.生产力
-
Generality.普适性
他们之间是三角关系,永远在平衡和拉扯中。
Parallelism is the way to go for those wanting to avail themselves of the full performance of their systems.并行是为了发挥机器的全部性能。

One of the inescapable consequences of the rapid decrease in the cost of hardware is that software productivity becomes increasingly important.硬件成本下降后,软件生产力的重要性得到了提高。
In fact, this economic force explains much of the maniacal focus on portability, which can be seen as an important special case of generality.为了兼容,总是要失去一些性能的。

总是要在performance, productivity, and generality中取得平衡,包括C/C++、Java、MPI等。

但也有其他的方法来提高性能:
-
Run multiple instances of a sequential application.
-
Make the application use existing parallel software.
-
Optimize the serial application.
1.If your program is analyzing a large number of different scenarios, or is analyzing a large number of independent data sets, one easy and effective approach is to create a single sequential program that carries out a single analysis, then use any of a number of scripting environments (for example the bash shell) to run a number of instances of
that sequential program in parallel.
用单一的结果运算脚本并行地去计算数据集的结果。
2.There is no longer any shortage of parallel software environments that can present a single-threaded programmingenvironment, including relational databases [Dat82], web-application servers, and map-reduce environments.
除了加入GPU外,还可以加入关系型数据库、web应用服务和map-reduce环境。
3.随着摩尔定律不能再来显著的单线程性能改进,并行编程将是打破性能瓶颈最好的选择。但数据结构与算法的选择仍然很重要,数据布局的调整也会提高性能,减少CPU等待磁盘的时间.
Of course, the easier it is to parallelize your program, the more attractive parallelization becomes as an optimization.

But parallel programming involves two-way communication, with a program’s performance and scalability being the communication from the machine to the human. In short, the human writes a program telling the computer what to do, and the computer critiques this program via the resulting performance and scalability. Therefore, appeals
to abstractions or to mathematical analyses will often be of severely limited utility.
但并行编程不仅是写代码,也会涉及到two-way communication双向通信,以及可伸缩性,还需要有抽象和数学分析能力。So,人为因素占比较大。
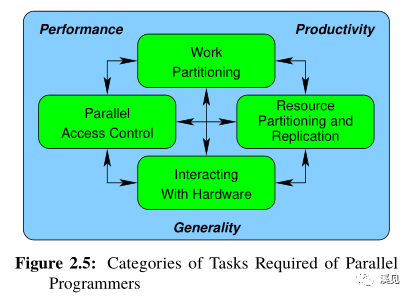
如图所言:对软件开发人员的要求较高。

Work Partitioning
良好的并行程序设计拥有适合的数据结构,而它所需要的state spaces以及I/O devices都很合理,也不会引起cpu caches,但糟糕的并行程序会引起争夺,及难以理解。
Parallel Access Control
The first parallel-access-control issue is whether the form of access to a given resource depends on that resource’s location.
The other parallel-access-control issue is how threads coordinate access to the resources.
同步永远会涉及到权限机制,deadlock, livelock, transaction rollback这些问题永远都在。
Resource Partitioning and Replication
The most effective parallel algorithms and systems exploit resource parallelism, so much so that it is usually wise to begin parallelization by partitioning your write-intensive resources and replicating frequently accessed read-mostly resources.
对写入密集型资源进行分区,以便于并行化资源的访问和复制,并随着时间动态改变。dynamically change the partitioning over time.
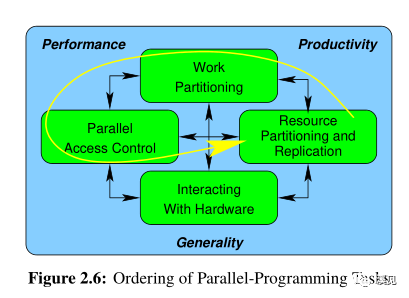
So,这就是并行编程的挑战。
Interacting With Hardware
Hardware interaction is normally the domain of the operating system, the compiler, libraries, or other software-environment infrastructure.
但涉及到性能的方向,我们就会想要压榨干机器的所有潜力,所以必须要理解与硬件的交互。以下都需要有所理解。
cache geometry,
system topology,
interconnect protocol of the target hardware.

Writing concurrent programs has a reputation for being exotic and difficult. I believe it is neither. You need a system that provides you with good primitives and suitable libraries, you need a basic caution and carefulness, you need an armory of useful techniques, and you need
to know of the common pitfalls. I hope that this paper has helped you towards sharing my belief.

1980年以来,
人类从未停下对并行编程的挑战,
所以根本没有理由拒绝,21世纪的今天所面临的挑战!
Chapter 3 Hardware and its Habits
This chapter therefore looks at the costof synchronization and communication within a shared-memory system.

CPU其实不是按照一条直线跑道在跑。
In contrast, the CPU of the late 1990s and of the 2000s execute many instructions simultaneously, using pipelines; superscalar techniques;
out-of-order instruction and data handling; speculative execution, and more [HP17, HP11] in order to optimize the flow of instructions and data through the CPU.

Pipelined CPUs
Suitable control flow can be provided by a program that executes primarily in tight loops, for example, arithmetic on large matrices or vectors.这其中有很多控制流,cpu在边猜测边执行,猜错的成本很高,对于可预测控制流程序运行良好,但涉及到非可预测的分支,cpu猜错后必须丢弃此前的所有分支指令,非常浪费时间。
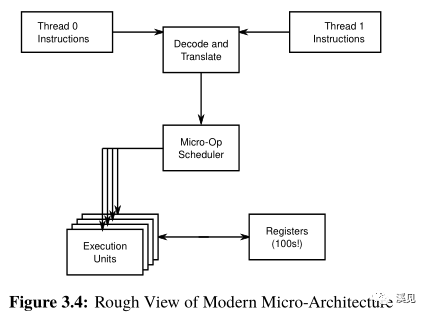
This gets even worse in the increasingly common case of hyperthreading (or SMT, if you prefer), especially on pipelined superscalar out-of-order CPU featuring speculative execution.
Therefore, the execution of one hardware thread can and often is perturbed by the actions of other hardware threads sharing that core.
n theory, this contention is avoidable, but in practice CPUs must choose very quickly and without the benefit of clairvoyance. In particular, adding an instruction to a tight loop can sometimes actually cause execution to speed up.
CPU运行得太快了,以至于对指令的判断能力跟不上。
Memory References
memory references often pose severe obstacles to modern CPUs.
these caches require highly predictabledata-access patterns to successfully hide those latencies.
nfortunately, common operations such as traversing a linked list have extremely unpredictable memory-access patterns.
延迟总是会成为cpu访问内存的困扰,当然原子操作也会。
Atomic Operations
even though they are in fact being executed piece-at-a-time, with one common trick being to identify all the cachelines containing the data to be atomically operated on, ensure that these cachelines are owned by the CPU executing the atomic operation, and only then proceed with the atomic operation while ensuring that these cachelines remained owned by this CPU.

Memory Barriers
Cache Misses
I/O Operations
在CSAPP书中,对于内存屏障、缓存未命中、以及IO操作有更全面的描述。

A major goal of parallel hardware design is to reduce this ratio as needed to achieve the relevant performance and scalability goals.
Overheads
Don’t design bridges in ignorance of materials, and don’t design low-level software in ignorance of the underlying hardware.

下面进入硬件系统架构。
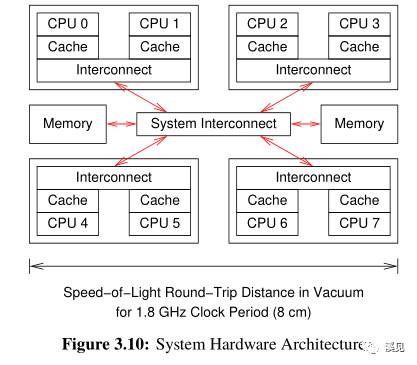
This simplified sequence is just the beginning of a discipline called cache-coherency protocols. 缓存一致性。

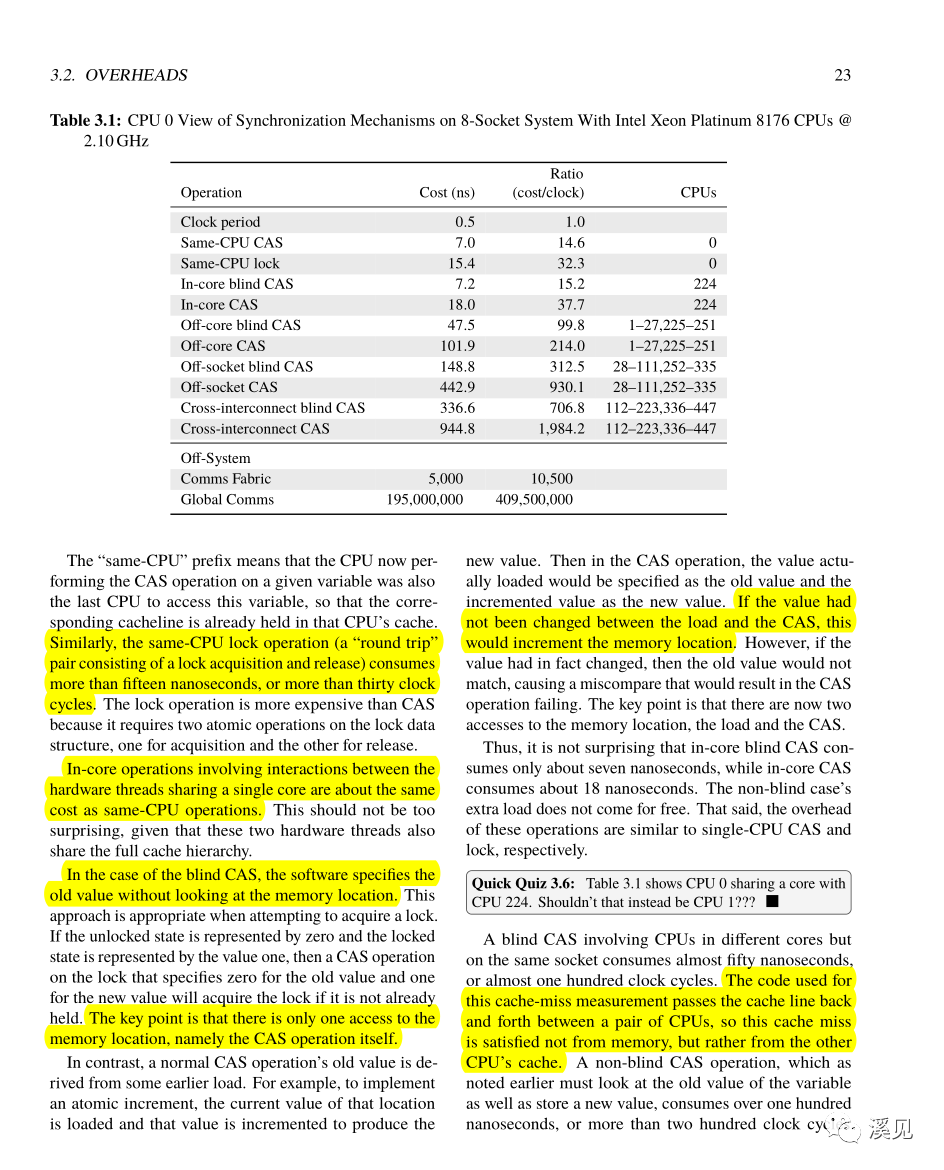
same-CPU compare-and-swap(CAS),CSAPP里也有讲到。
这里讲得很细,建议直接看原文吧。
CAS is an atomic operation in which the hardware compares the contents of the specified memory location to a specified “old” value, and if they compare equal, stores a specified “new” value, in which case the CAS operation succeeds.这里涉及到很多优化和计算方式的改变。
Hardware Optimizations
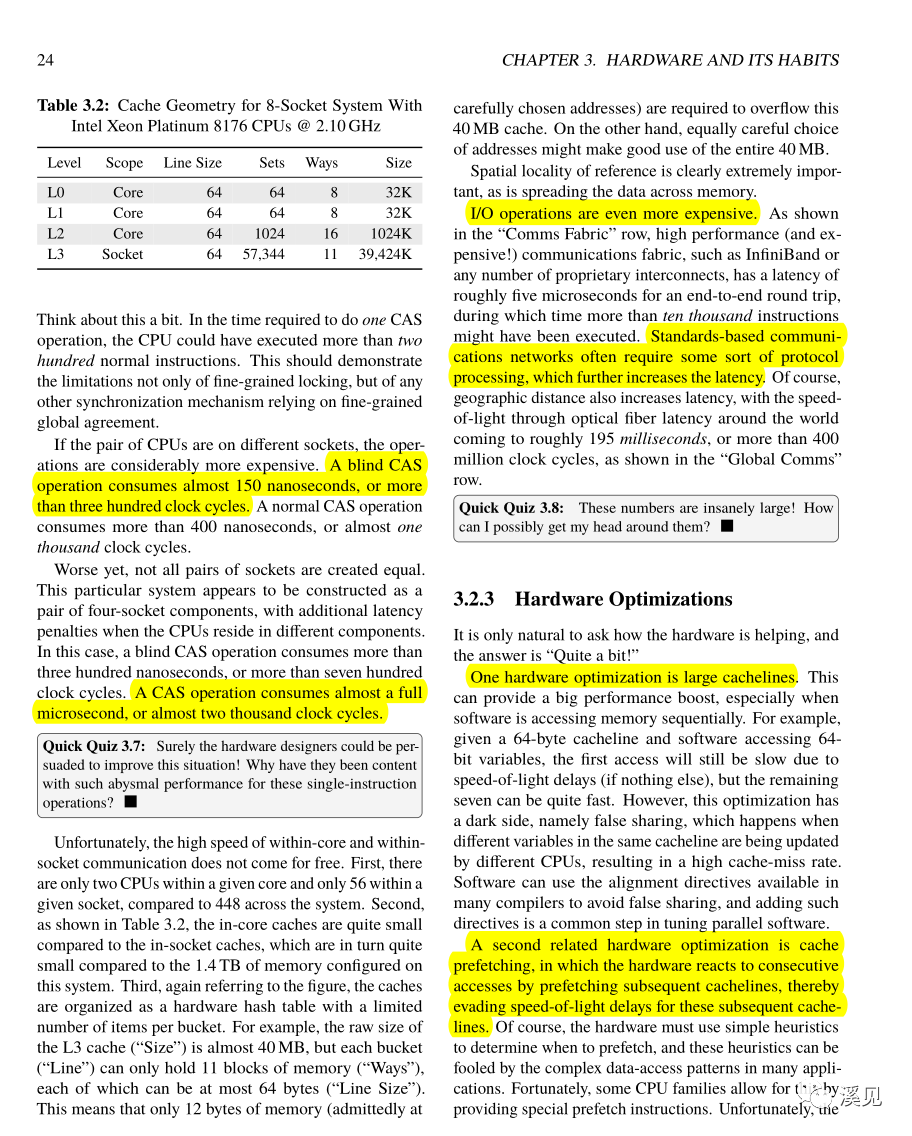
1.One hardware optimization is large cachelines.
2.A second related hardware optimization is cache prefetching, in which the hardware reacts to consecutive accesses by prefetching subsequent cachelines, thereby evading speed-of-light delays for these subsequent cache-lines.
3.A third hardware optimization is the store buffer, whichallows a string of store instructions to execute quickly even when the stores are to non-consecutive addresses and when none of the needed cachelines are present in the CPU’s cache.
4.A fourth hardware optimization is speculative execution, which can allow the hardware to make good use of the store buffers without resulting in memory misordering.
5.A fifth hardware optimization is large caches, allowing individual CPUs to operate on larger datasets without incurring expensive cache misses.
6.A final hardware optimization is read-mostly replication, in which data that is frequently read but rarely updated is present in all CPUs’ caches.
Hardware Free Lunch?
The major reason that concurrency has been receiving somuch focus over the past few years is the end of Moore’s-Law induced single-threaded performance increases.
摩尔定律的终结,带来对并发的关注。
但是任何事物都是有代价的。

现在开始谈3D集成了。
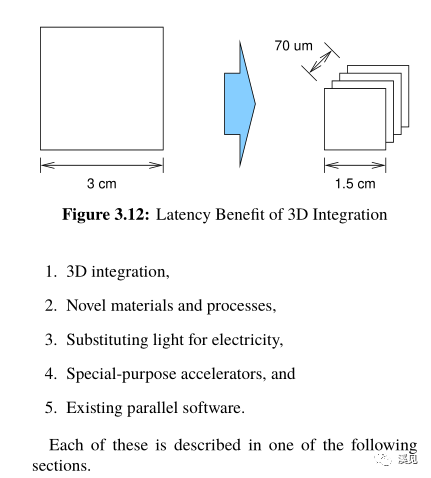
好吧,数电模电没好好学,流下悔恨的眼泪…….

Special-Purpose Accelerators
专用的并行编程加速器
Existing Parallel Software
其实现有的并行软件也能解决部分的工业问题。
Software Design Implications
The lesson should be quite clear: Parallel algorithms must be explicitly designed with these hardware properties firmly in mind.

Ok,第三章结束!
主要讲得是如何实现出色的并行性能和可扩展性,大量的底层细节。
最后问大家一个问题吧。
Question:
OK, if we are going to have to apply distributed-programming techniques to shared-memory parallel programs, why not just always use these distributed techniques and dispense with shared memory?
Answer:
Because it is often the case that only a small fraction of the program is performance-critical. Shared-memory parallelism allows us to focus distributed-programming techniques on that small fraction, allowing simpler shared-memory techniques to be used on the non-performance-critical bulk of the program.
未完待续~
感谢阅读到这里,周末愉快~